Be Cloud-Agnostic: A Solution for Computing on Genomics Datasets in Distributed Cloud Locations
The Multi-Cloud features on the Seven Bridges Platform allow you to work in a “cloud-agnostic” manner, enabling researchers to access and compute on datasets stored on multiple cloud locations to save time and money.
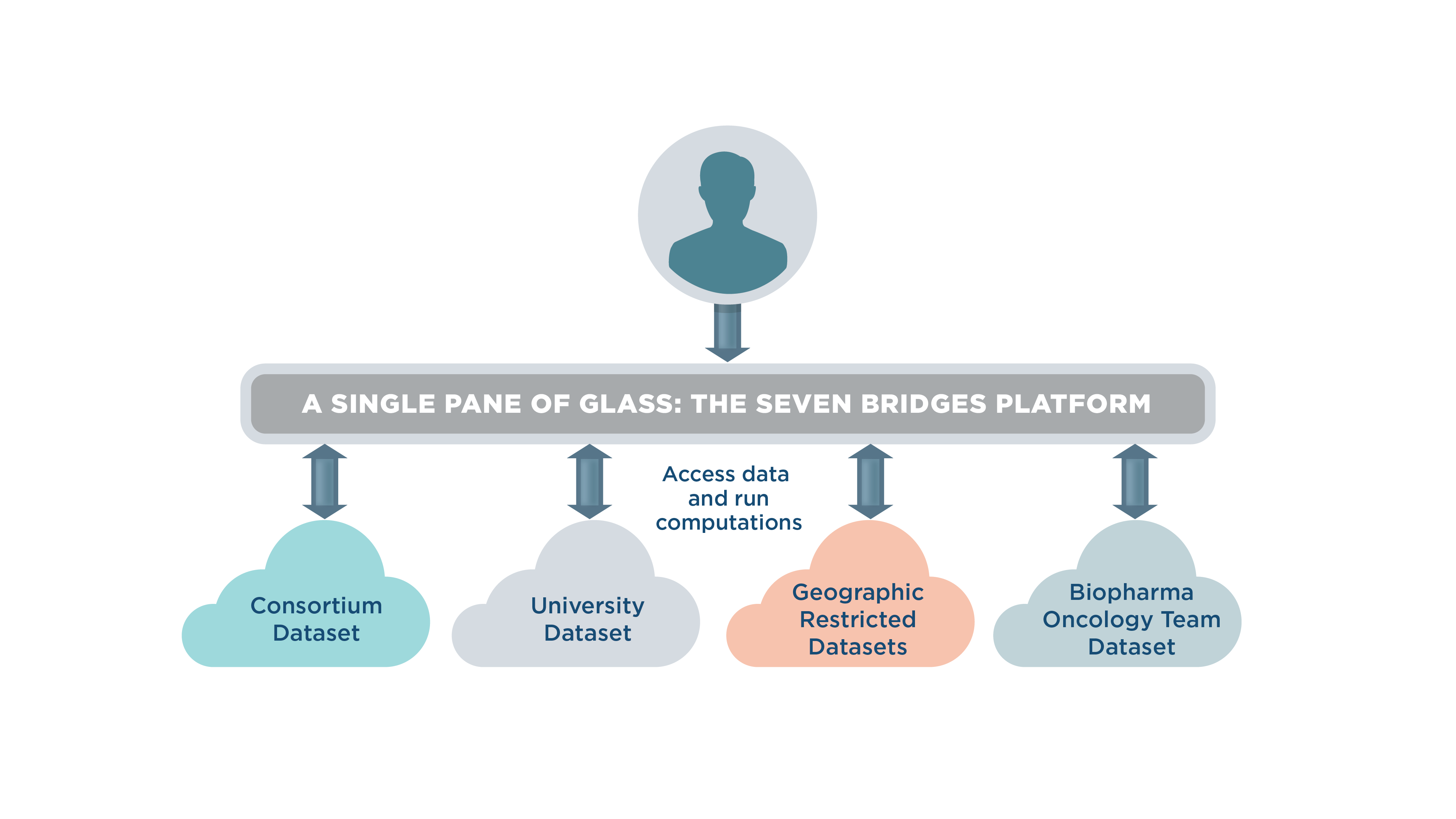
Empower your research with relevant datasets regardless of where the data lives
Starting a research project with data distributed in multi-cloud environments can be daunting. First, you need to know where your datasets of interest reside. Specifically, which provider is hosting the datasets and in which regions? Beware, some datasets must remain in specific cloud locations due to policy restrictions, which may create another barrier between you and the data you need. On top of that, the logistics of downloading, storing, and running computations on datasets locally can be cumbersome, and the specter of data egress costs is a common concern. Do you have the time, money, and equipment to run computations on the data locally instead of in the cloud? As you can see, the information that you need to know before you can even begin a project can be difficult to find, and the sheer volume of details to keep track of is just another distraction from your research.
So, how did we at Seven Bridges make this process easier? You told us you want to access datasets regardless of where they are stored, and to compute only on that data on its given cloud location. You asked for the tools to make informed decisions about how and where to run your computation. And you want to save some time and money while you’re at it. Well, we listened.
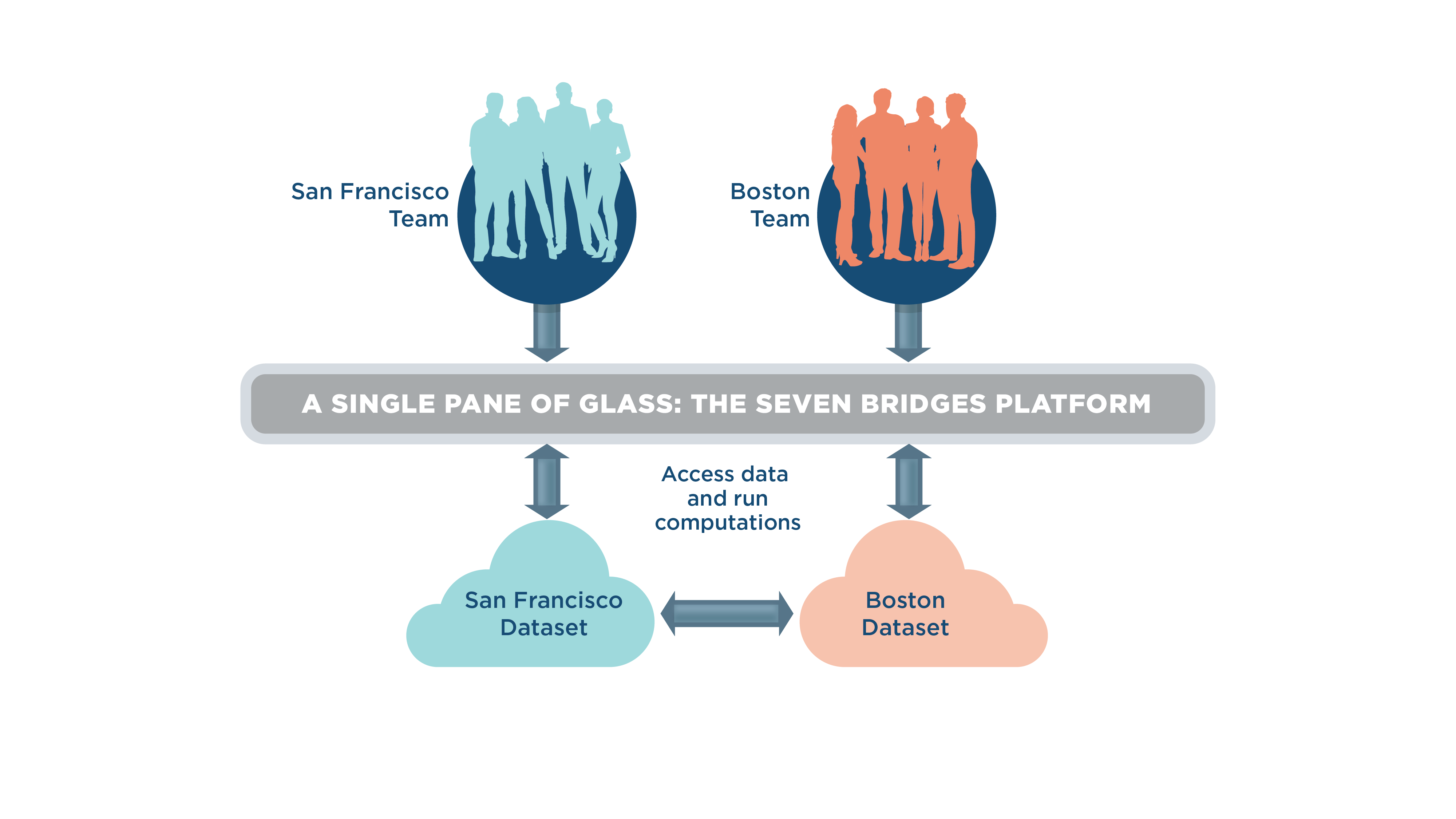
A single pane of glass: one platform with support for multiple cloud locations
The Seven Bridges Platform solves the distributed data problem by acting as a “single pane of glass:” a platform that can run computations on data distributed across cloud providers from one user interface. Currently, the Seven Bridges Platform is featured on both Amazon Web Services and Google Cloud environments. But why is this “single pane of glass” approach so useful?
Suppose you are a researcher for a pharmaceutical company based in San Francisco storing data in a western US cloud location. Meanwhile, your colleague in the Boston-based branch of the same company is storing their data in an eastern US cloud location. You both want to log into the same platform, run analysis on the combined data, and then compute on results together in one location for future analysis. With most other biomedical data analysis platforms, there simply is not a streamlined method to do so, and it is costly to duplicate datasets and administration/billing systems to host them again in new cloud locations to run computations.
Ideally, you would want to use one platform with support for multiple cloud locations so that from one user interface, you could find and access data on different cloud locations and then choose to run computation there where the data is stored. The Seven Bridges Platform’s cloud-agnostic approach achieves this and empowers you to:
- combine distributed datasets together for streamlined analysis with colleagues.
- remain compliant when your desired dataset is not permitted to leave a specific geographic location.
- avoid unnecessary data egress costs from moving your data around to run a computation in a different cloud or region from where the data is hosted.
Using the Seven Bridges Platform allows you to focus more on the science of your analysis, not on the logistics. No other biomedical data analysis company can offer this degree of multi-cloud support for genomics research.
Save time and money by computing on data where it lives
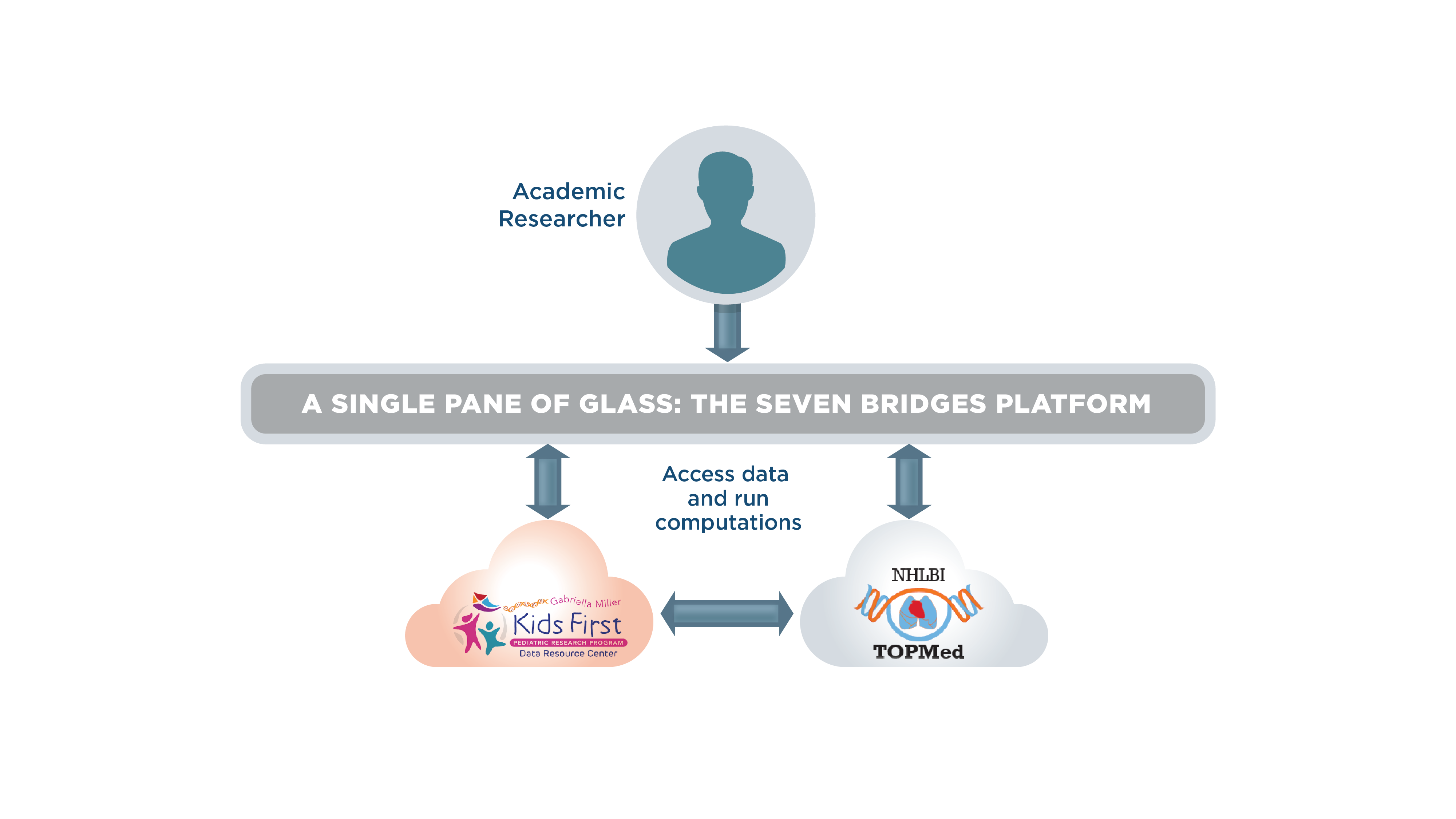
Now suppose you are an academic researcher who wants to perform a genome-wide association study (GWAS) using both the public Kids First dataset which is on the Amazon US-east-1 cloud and datasets from the NHLBI Transomics for Precision Medicine Initiative stored on the Google US-east-1 cloud. You want to combine data from multiple distributed datasets and run GWAS analyses.
 Ordinarily, when running an analysis with input files from different cloud locations, there will be data egress when moving the data from one cloud location to the other for computation. Working with raw FASTQ or CRAM/BAM files means large volumes of data, and thus more time and money required to move them. And just how much time and money will be needed is not readily apparent. Without a cloud-agnostic option, you would have to make the judgment call of which dataset needs to be moved, and in which cloud location the computation will be run. These issues with data egress have been a thorn in the side of the genomics research community.
Ordinarily, when running an analysis with input files from different cloud locations, there will be data egress when moving the data from one cloud location to the other for computation. Working with raw FASTQ or CRAM/BAM files means large volumes of data, and thus more time and money required to move them. And just how much time and money will be needed is not readily apparent. Without a cloud-agnostic option, you would have to make the judgment call of which dataset needs to be moved, and in which cloud location the computation will be run. These issues with data egress have been a thorn in the side of the genomics research community.
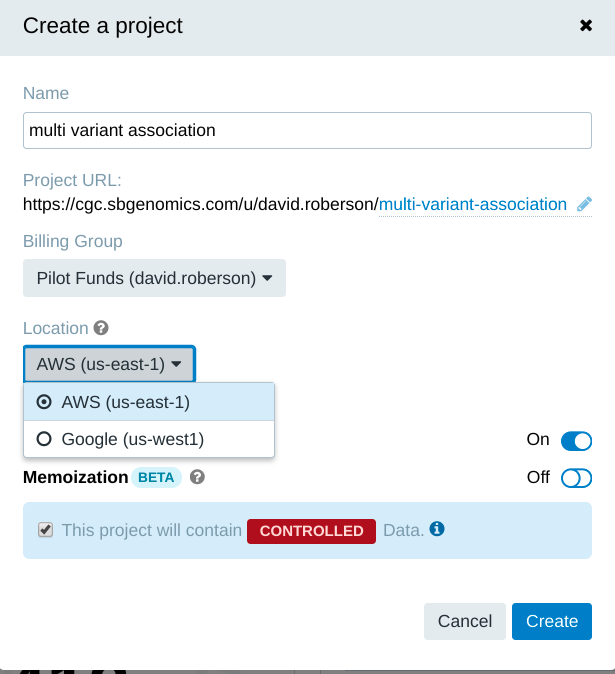
To solve these issues in the example above, the Seven Bridges Platform will start a computational instance on Amazon US-east-1 upon initiating the workflow. Hovering your cursor over the name of the project allows you to see its cloud location.

In this example, the input file on Amazon, the input file on Google, and the tools will all be transferred to the computational instance and then the output files will be stored on Amazon US-east-1. As you set up your analysis workflow and tools, warning messages about additional costs will appear if you add an input file from a different cloud location.
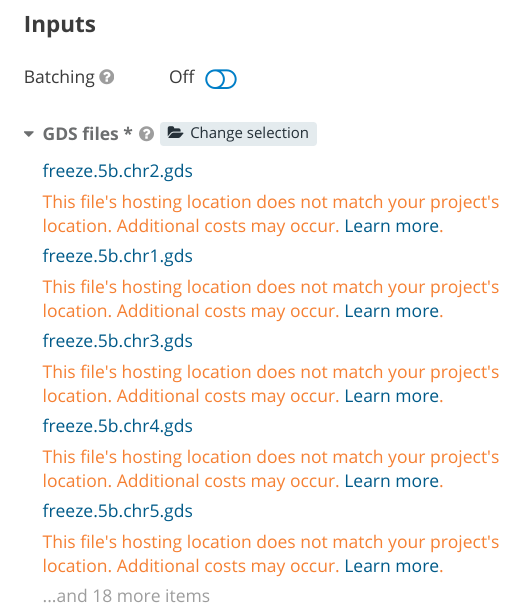 Since the FASTQ and CRAM/BAM files are large and we don’t want to move them, the Seven Bridges Platform can instead call variants on them in their respective cloud location and then move these variant call format files (VCFs) across clouds. There will be some data egress, but VCFs are much smaller than FASTQ/CRAM/BAM files and thus the data egress cost and time requirements are much lower.
Since the FASTQ and CRAM/BAM files are large and we don’t want to move them, the Seven Bridges Platform can instead call variants on them in their respective cloud location and then move these variant call format files (VCFs) across clouds. There will be some data egress, but VCFs are much smaller than FASTQ/CRAM/BAM files and thus the data egress cost and time requirements are much lower.
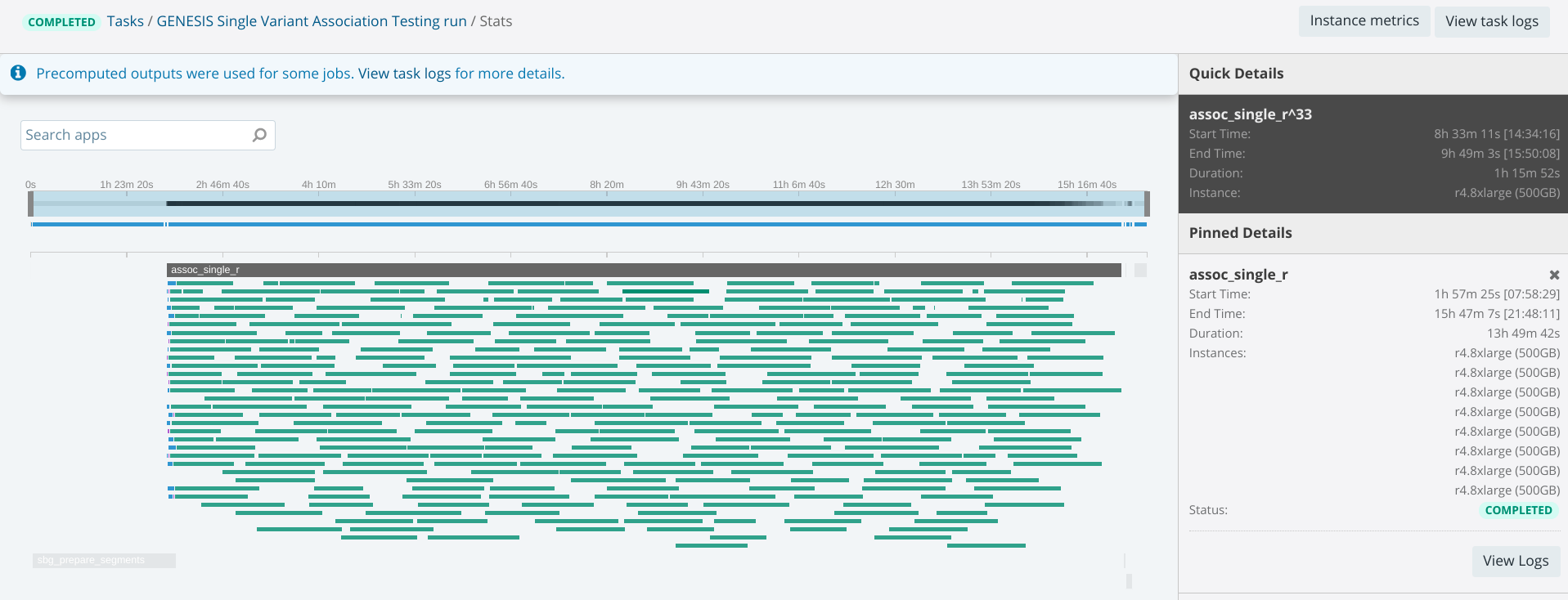 When the task containing such files is completed, the cost of data transfer is included in the total costs of task execution and you can also see a breakdown of the total transfer cost, attached disks, and instances. With these features to guide you, you will have everything you need to make informed decisions about how to run your analysis to fit your particular timeline and budget.
When the task containing such files is completed, the cost of data transfer is included in the total costs of task execution and you can also see a breakdown of the total transfer cost, attached disks, and instances. With these features to guide you, you will have everything you need to make informed decisions about how to run your analysis to fit your particular timeline and budget.
Have questions about the Seven Bridges Platform and about our Multi-Cloud features?
Feel free to contact us to discuss how these features can help accelerate your own path from data to discovery.