Customizing your tasks on the Seven Bridges Platform
Using hints to cusomize tasks
This blog post provides an overview of how hints can be used to customize tasks on the Seven Bridges Platform. In the context of the Platform, “hints” are parameters that allow you to configure or override some of the predefined ways in which apps and tasks work. Specifically, hints can be used to:
- Set up CPU and memory requirements for a tool’s execution.
- Explicitly state the instance on which you want a tool to run and set the maximum number of parallel instances.
- Define which files produced by a tool will be caught as log files.
Hints format
Hints are entered as key – value pairs. Available keys for task-related hints are:
| Hint | Datatype of value | Description |
| sbg:AWSInstanceType or sbg:GoogleInstanceType | string | Defines which specific AWS or Google Cloud Platform instance is needed to run the task. Read more. |
| sbg:maxNumberOfParallelInstances | integer | Defines how many instances can be run in parallel. Read more. |
| Hint | Datatype of value | Description |
| sbg:CPURequirement | integer | Defines the number of CPUs required to run a tool. Read more. |
| sbg:MemRequirement | integer | Specifies the memory needed for execution of a tool. Read more. |
| sbg:SaveLogs | string | Uses a regular expression for pattern matching to set which files will be caught as log files. Read more. |
For example, if you want to define the maximum number of instances which can run in parallel, the hint would be:
| Key | Value |
| sbg:maxNumberOfParllelInstances | 4 |
CPU and memory requirements
You can set the required CPU and memory for any tool, which is done by one of Seven Bridges’ bioinformaticians in case of a publicly available tool or by yourself if this is a tool that you wrapped for use on the Platform. When a tool is first added to the Platform, the default values in the CPU and Memory (MB) fields are 1 CPU and 1000 MB of memory, but they should be checked and adjusted to match the tool’s needs.
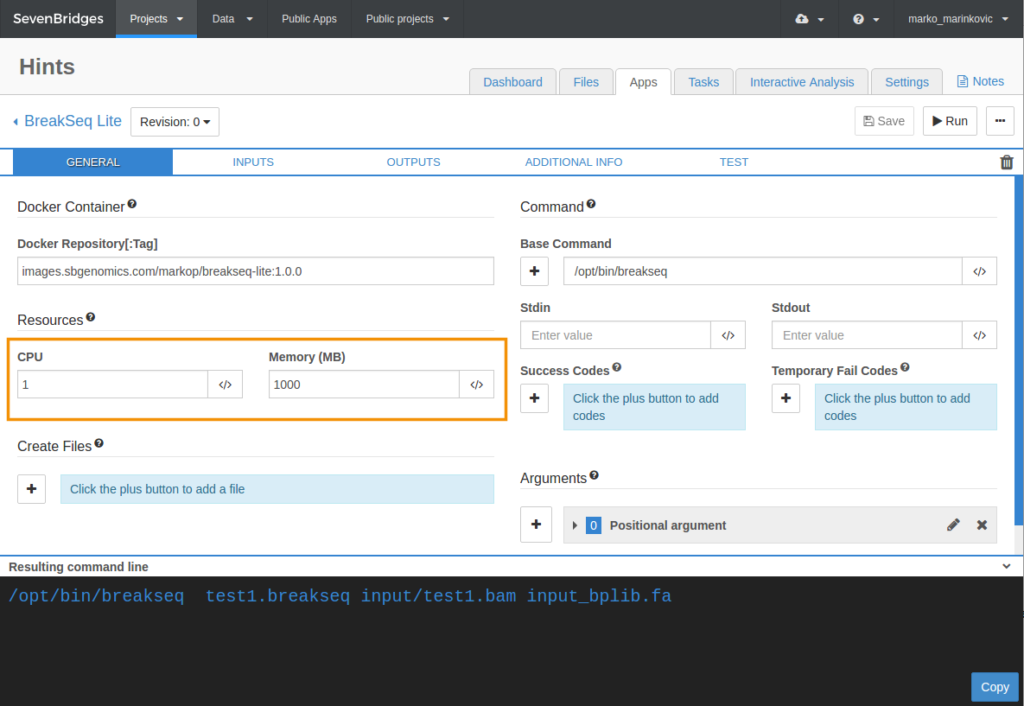
CPU and memory requirements are automatically reflected as the following hints in the tool’s settings:
- sbg:CPURequirement
- sbg:MemRequirement
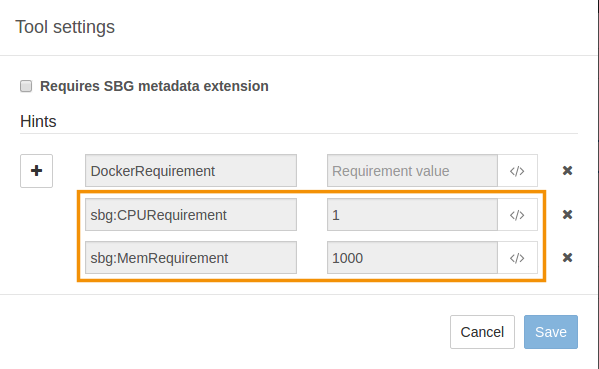
sbg:CPURequirement and sbg:MemRequirement hints are read-only. CPU and memory parameters can only be modified in the CPU and Memory (MB) fields on the General tab in the tool editor.
Instance type and the number of parallel instances
Each tool that is run in a task is executed on a computation instance in the cloud. Instances are virtual computers; different instance types have different allocations of CPU and memory, so are suited for workloads with different computational requirements.
The Platform uses a scheduling algorithm to select an appropriate computation instance for each tool that is run in a task. The scheduling algorithm assigns an instance that has sufficient resources to run the tool and is also optimized to efficiently pack tools onto instances when running workflows made of multiple tools. Even though the scheduling algorithm will select a default instance that is suitable for your task, in some cases you might want to override the algorithm to select a specific instance type to run the task on. This is done using instance-related hints which are listed below:
- sbg:AWSInstanceType or sbg:GoogleInstanceType – Allows you to define the specific instance you would like to use depending, respectively, on whether you run the Seven Bridges Platform on AWS or Google Cloud Platform. When you start typing the instance name in the Requirement value field, you will see automatically generated suggestions in the drop-down box.
- sbg:maxNumberOfParallelInstances – Takes an integer value that defines how many instances can be run in parallel for a workflow.
The following image shows how instance type and number of parallel instances are set up for a workflow using hints.
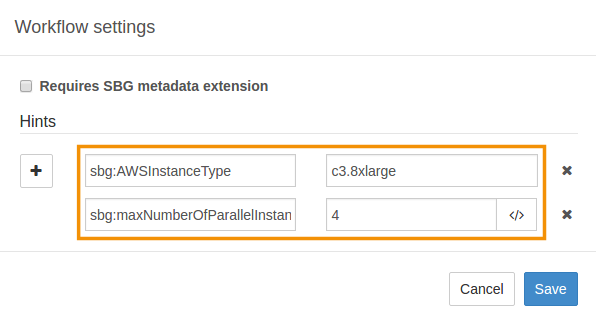
You can override the scheduling algorithm in a number of ways:
- You can set the instance type for an entire workflow. This will override any setting that you have made for any given tool in the workflow.
- You can set the instance type for any tool(either one you have added to the Platform yourself, using the SDK, or a public tool) using the tool editor. This will override the instance type selected by the scheduler.
- You can set the instance type for any tool(s) in a workflow. This will override any setting you have made in the tool editor.
Read more about setting up computation instances and see the list of available instance types.
If you override the instance type that the scheduling algorithm selects, you may inadvertently select one that doesn’t have enough resources to run the app successfully. To make sure you pick a suitable instance, you need to check the required resources of the tool you want to use by opening the tool’s properties in the the tool editor.
Configure log files for your tool
Hints can also be used when defining which files produced by a tool will be treated as log files, and presented as the logs of a task on the view task logs page and via the API request to get task execution details. The default filter for catching the log files finds all files in the working directory of the job that match *.log, (including err.log, and cmd.log). The visual interface view task logs page additionally shows job.json and cwl.output.json). You can add to the files presented as logs by defining a custom file extension or file name, that will catch all matching files and present them as logs. The following hint is used for this purpose:
- sbg:SaveLogs – Allows you to define a file name or file extension for the log files.
The image below shows an example of sbg:SaveLogs defined for a tool. The configuration shown will save reports.txt and all files with the .err extension as log files, in addition to the default logs.
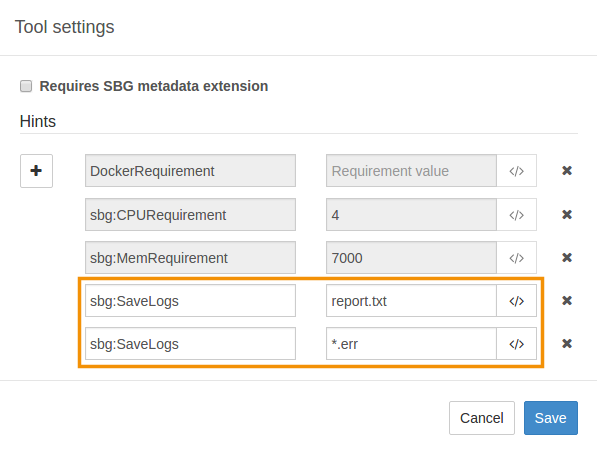
You are able to add as many sbg:SaveLogs hints as you like in order to define different log file names and/or extensions.
See the steps on how to configure log files for your tool.